Seit kurzem bastel ich an einem Streaming-Setup für den Sneakpod. Ziel ist es die Sendungen live zu streamen, aber nach wie vor lokal aufzunehmen. Im Anschluß an die Live-Sendung steht die normale Nachbearbeitung um dann eine neue Podcast-Folge zu veröffentlichen. Dazu habe ich mich mal in Icecast und die Möglichkeiten vom Mac zu streamen vergraben möchte das derzeitige Setup kurz darlegen.
In der Artikelserie zum Thema Podcast-Setup habe ich das grundsätzliche Setup unseres Podcasts (aus damaliger Sicht) bereits dargelegt, bei Bedarf (schreibt Kommentare) werde ich da vielleicht nochmal ein Update geben, da sich schon einiges geändert hat.
Protokolle
Da ich erstmal das Thema Streaming überhaupt an den Start bringen wollte und mir das Thema HTTP-LiveStreaming zwar schon verlockend vorkam, aber dann doch (noch) sehr Apple-zentrisch ist, fiel die Wahl erstmal auf klassisches Icecast/SHOUTcast-Streaming. Das geht auch über HTTP, macht allerdings noch nicht so den ganzen modernen Foo mit unterschiedlichen Qualitätsstufen und ist natürlich auch nicht in der Lage als Nebenprodukt eine Re-Live-Möglichkeit abzuwerfen. Dafür gibt es für Icecast eine breite Unterstützung an Clients auf Hörerseite, dazu aber später mehr.
Eine Entscheidung für bestimmte Audioformate muss man an dieser Stelle noch nicht treffen, da sowohl HTTP-LiveStreaming, als auch Icecast-Streams in MP3, AAC und Vorbis streamen können. Jedoch habe ich mich entschlossen 2 Streams parallel anzubieten. Zu ersteinmal einen MP3-Stream und zum anderen einen AAC(HE)-Stream.
MP3-Stream
MP3 dürfte da draußen in der weiten Welt immer noch den kleinsten gemeinsamen Nenner darstellen wenn es um Massenkompatibilität geht, also müssen wir natürlich in MP3-Streamen. Um den Server bei mehr Hörern zu schonen streamen wir nur in Mono und zwar mit 64kBit/s (ABR).
AAC(HE)-Stream
Den AAC-Stream bieten wir mit niedrigerer Bitrate speziell mit Hintergedanken an Verbindungen mit sehr niedriger Bandbreite an. Solltet Ihr also beispielsweise vorhaben uns von unterwegs über UMTS (oder schlimmer), bespielsweise am Handy, zu hören dann ist dieser Stream mit nur 32kBit/s ABR der Richtige. Der Decoder den Ihr einsetzt sollte aber auf jeden Fall High Efficiency-AAC unterstützen, sonst klingt der Stream eher fürchterlich.
Server
Hardware und Bandbreite
Als Server verwenden wir ((bis auf weiteres)) unseren normalen Sneakpod.de-Server, auf dem auch dieses Blog läuft. Wieviele Hörer der aushält ist vorerst unbekannt. Je nachdem ob die Bandbreite oder die CPU-Last den Stream als erstes killt. Vorerst halten sich die Hörerzahlen unserer bisherigen Experimente stark in Grenzen und wir werden erstmal sehen müssen wie das weitergeht. Eine kleine Beispielrechnung sagt mir das man unseren beiden Streams (zusammen 96kBit/s) über 1000x parallel über eine 100MBit/s-Anbindung schieben könnte – ich gehe daher davon aus, dass der Server vorher an seinen eigenen Querelen (aka CPU-Last) eingeht.
Software
Der Server läuft, nach wie vor, unter CentOS und dort habe ich Icecast2 installiert. In der Datei /etc/icecast2.xml kann man nun so diverse Limits für den Server einstellen. Ich habe hier das meiste bei den Defaults belassen.
<clients>100</clients> limitiert uns erstmal auf 100 Zuhörer, keine Ahnung ob der Server das überhaupt mitmacht, aber bislang haben wir dieses Limit noch nicht erreicht – wenn es so kommt sehen wir weiter.
Die Zugangsdaten legt man im Bereich authentication fest, hier trägt man Usernamen und Passwörter für die Source-Clients ein, also die Daten, mit denen man sich später anmeldet um etwas über diesen Server zu streamen.
Im unteren Bereich der XML-Datei muss man noch die Pfade für’s webroot anpassen, damit Icecast seine eigenen Webseiten richtig ausliefern kann, man wählt sich einen Port ≠ 80 um dem normalen Webserver nicht auf die Füße zu treten.
Source-Clients
Unsere Audiodaten, also unser Podcast ensteht ja aber logischerweise nicht auf dem Server, sondern irgendwo im Studio und da haben wir maximal einen Laptop. Natürlich streamt man nicht von diesem Laptop zu allen Zuhörern, sondern von dort aus nur mit einem Stream zum Server und dieser verteilt den Stream an die Hörer. Wir sind also für den Server eine sogenannte Source, eine Quelle, und brauchen dafür eine Client-Software um den Icecast-Server zu füttern. Da ich den Stream mit einem Mac betreibe kommen eigentlich nur 2 Produkte in Frage: Ladiocast oder Nicecast. Ersteres ist eine kostenlose japanische Software, zweiteres ein Rogue Amoeba-Produkt das Geld (($59 um genau zu sein)) kostet.
Ladiocast
Die Entscheidung fiel also erstmal auf Ladiocast und das muss man nun einrichten. Ladiocast kann 2 Streams gleichzeitig aussenden, somit können die beiden oben erwähnten Streams problemlos konfiguriert werden.
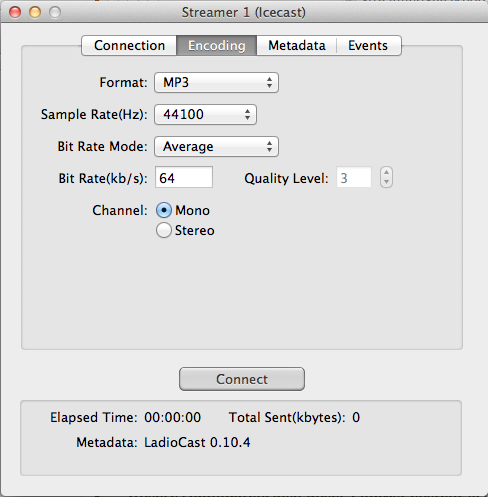
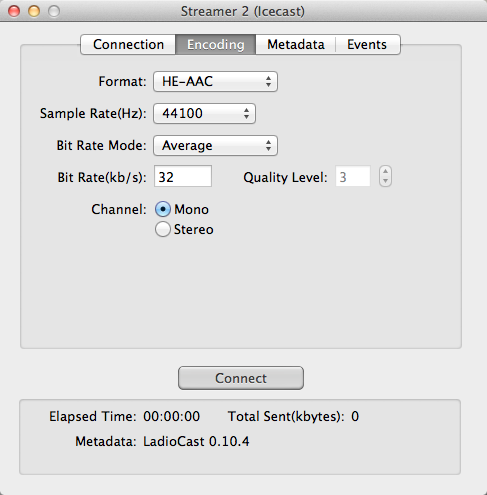
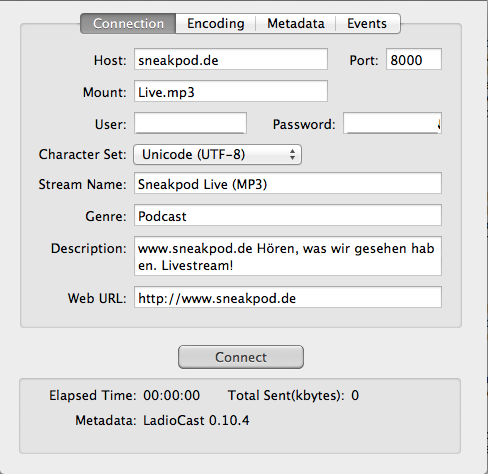
Gestreamt wird zu sogenannten Mountpoints. Effektiv sehen diese für den Webbrowser wie Ressourcen hinter einem URL aus. Dieser kann, in der Standardkonfiguration durch die Source festgelegt werden ((es lassen sich auch feste Mountpoints in der .xml-Datei festlegen)). In unserem Fall legen wir die Mountpoints Live.mp3 und Live.heaac durch die Einstellungen in Ladiocast fest.
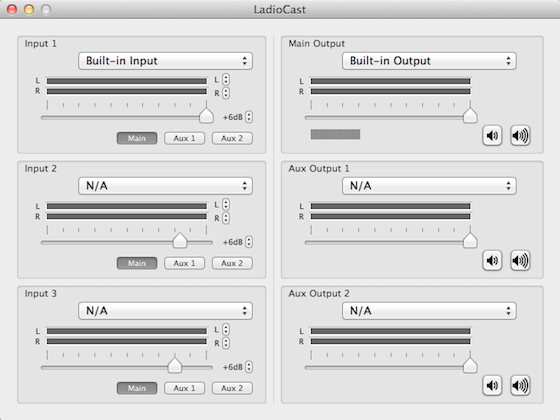
Ladiocast besitzt im Haupfenster Mix-Möglichkeiten für den Main-Mix und zwei separate AUX-Mixe, in unserem Setup kommt diese Funktion allerdings nicht zum Einsatz. Wir geben einfach ein Line-In auf den Output, fertig. Das Line-In kommt im Falle einer Aufnahme über Skype oder bei mir im Heimstudio aus dem Mischpult ((dann auch über ein anderes Interface, aber ich schweife ab)) oder, im Falle einer Aufnahme über Stefans H2, direkt aus dem Aufnahmegerät.
Listening-Clients
Kommen wir zur Seite des Hörers. Um den Stream zu empfangen benötigt man natürlich eine Software die in der Lage ist auf den Streaming-URL zuzugreifen und Audio zur Ausgabe zu bringen. Hierzu gibt es unzählige Möglichkeiten, einige hatte ich bereits auf www.sneakpod.de/Live-Stream/ gelistet. Das vorgehen ist jedoch immer das gleiche – spielen wir das am Beispiel von VLC ((das gibt es für nahezu alle Platformen)) einmal durch.
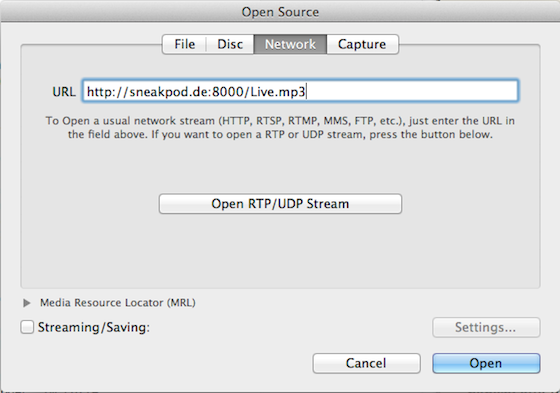
Als erstes wählt man aus dem Menü Open Network...

um als nächstes den Stream-URL einzugeben und zu öffnen. Fertig. Mehr ist nicht zu tun, auch wenn es natürlich nur wirklich funktioniert während wir streamen. In der übrigen Zeit bekommt man eine Fehlermeldung. :-(
Qualität
Audioqualität
In meinen Testaufbauten war ich mit der Streamqualität ((rein was das Audioencoding anging)) recht zufrieden, auch wenn ich von einigen Hörern nach der ersten gestreamten Sendung das Feedback bekommen habe, dass zu wenig Pegel auf dem Stream gewesen sei – das wird zu erforschen bleiben.
Latenz
Die Latenz, also die Verzögerung zwischen dem wirklich gesprochenen Wort und dem Augenblick in dem die Zuhörer es hören können, liegt irgendwo zwischen 5 und 10 Sekunden. Scheint für diese Art von Streaming ein übliche Größe zu sein, stellt kein großes Problem dar und macht sich immer sehr unterhaltsam in Chat bemerkbar.
Chat
Was wäre eine Live-Sendung auch ohne Chat. Natürlich haben auch wir einen. #Sneakpod auf Freenode. Wie man da hinkommt steht auch auf www.sneakpod.de/Live-Stream/.
Interessant? Lust mehr zu erfahren? Schreibt Kommentare.
BTW: Dies ist der erste Artikel im Blog den ich mithilfe von Markdown geschrieben habe – hat gut geklappt – ging entspannt und schnell von der Hand und ich könnte mir vorstellen das in einem zukünftigen Artikel zu beleuchten.


